Node的强大永远都想不到,今天用Node做个简单的数据采集。
cheerio
Cheerio是一个快速、灵活且精益的jQuery核心实现,用于在Node.js环境中解析HTML文档。它可以帮助您在服务器端轻松地从HTML文档中提取数据,比如从网页中提取文章标题、内容、图片等信息。
使用Cheerio的好处是它非常轻量级,因此可以很快地加载和解析HTML文档。此外,Cheerio的API与jQuery非常相似,因此如果您熟悉jQuery,那么学习和使用Cheerio也会非常容易。
安装依赖
npm install cheerio
准备爬取的网站
我们来爬大家最熟悉的游戏王者荣耀英雄资料,哈哈哈哈。
爬取的地址https://pvp.qq.com/web201605/herolist.shtml
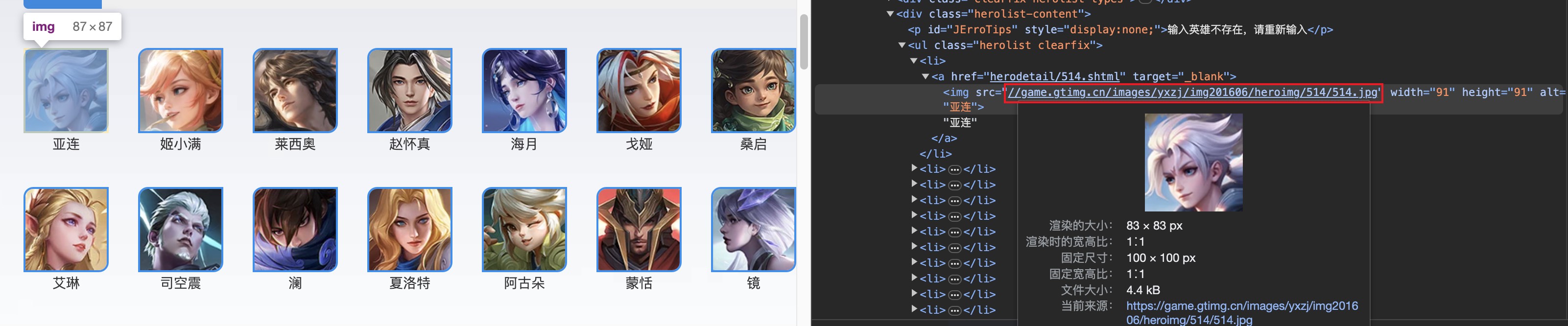
查看网页代码,分析页面布局结构,我们看到所有的图片都在herolist类名下的li a img里面。
编写代码
https用来发送请求的模块 (也可以使用request, axios)。
const https = require('https')
const cheerio = require('cheerio')
const HOST = 'https://pvp.qq.com/web201605/herolist.shtml'
const PROTOCOL = 'https:'
// 创建请求对象
const req = https.request(HOST,(res) => {
const contents = []
res.on('data',msg =>{
contents.push(msg)
})
res.on('end',()=>{
//得到整个HTML网页内容
const htmlStr = Buffer.concat(contents).toString('utf-8')
//使用cheerio加载HTML
const $ = cheerio.load(htmlStr)
// 获取图片列表
// encodeURI 为了防止图片地址存在中文无法下载,这里需要用encodeURI转base64
const imgList = Array.prototype.map.call(
$('.herolist li img'),
item => encodeURI(PROTOCOL + $(item).attr('src'))
)
console.log(imgList)
})
})
// 发送请求
req.end()
输出
[
'https://game.gtimg.cn/images/yxzj/img201606/heroimg/506/506.jpg',
'https://game.gtimg.cn/images/yxzj/img201606/heroimg/505/505.jpg',
'https://game.gtimg.cn/images/yxzj/img201606/heroimg/529/529.jpg',
.........
]
下载图片
download用来下载图片的模块
安装
npm install download
使用
const downLoad = require('download')
...
// 下载图片
//url 图片地址
//imgs 存放图片的目录
Promise.all(imgList.map(url => downLoad(url, 'imgs')));
以上方法只能爬取静态页面数,cheerio做一些简单数据采集是没问题的。
而且cheerio方式爬取网站容易被封ip,会遭到网站反爬虫机制的限制。
爬取动态数据
现在大多数网站都采取前后端分离的方式,前端网页都没有渲染HTMl。所以如果使用相同方式来获取目标网站的HTML页面,是获取不到dom的。
此时,如果还希望使用当前方法爬取数据,就需要分析该网站的ajax请求是如何发送的,可以打开浏览器开发者工具查看network面板来查看接口请求。
分析得出对应的ajax请求后,找到其URL,向其发送请求即可。
现在我们来获取boss直聘上的招聘列表。
爬取目标:https://www.zhipin.com/wapi/zpgeek/search/joblist.json?scene=1&query=%E9%AB%98%E7%BA%A7%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&city=101270100 &experience=&payType=&partTime=°ree=&industry=&scale=&stage=&position= &jobType=&salary=&multiBusinessDistrict=&multiSubway=&page=1&pageSize=30
const https = require('https')
const HOST = 'https://www.zhipin.com/wapi/zpgeek/search/joblist.json?scene=1&query=%E9%AB%98%E7%BA%A7%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&city=101270100&experience=&payType=&partTime=°ree=&industry=&scale=&stage=&position=&jobType=&salary=&multiBusinessDistrict=&multiSubway=&page=1&pageSize=30'
// 创建请求对象
const req = https.request(HOST,(res) => {
const contents = []
res.on('data',msg =>{
contents.push(msg)
})
res.on('end',()=>{
const res = Buffer.concat(contents).toString('utf-8')
console.log(res)
})
})
// 发送请求
req.end()
输出
{"code":37,"message":"您的访问行为异常.","zpData":{"name":"480db4cd","seed":"DPDAB6bmDhwv++plZKLG27Q7qoHAZNLS2xxatByYocA=","ts":1698929071931}}
可以看到遇到请求限制,这时可以模拟真实浏览器的请求头。
const https = require('https')
const HOST = 'https://www.zhipin.com/wapi/zpgeek/search/joblist.json?scene=1&query=%E9%AB%98%E7%BA%A7%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&city=101270100&experience=&payType=&partTime=°ree=&industry=&scale=&stage=&position=&jobType=&salary=&multiBusinessDistrict=&multiSubway=&page=1&pageSize=30'
// 创建请求对象
const req = https.request(HOST,{
headers: {
"method":"GET",
"path":".....",
"scheme":"https",
"Accept":"application/json, text/plain, */*",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cache-Control":"no-cache",
"Cookie":".....",
"Pragma":"no-cache",
"Referer":"https://www.zhipin.com/web/geek/job?query=%E9%AB%98%E7%BA%A7%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&city=101270100",
"Sec-Ch-Ua":"'Chromium';v='118', 'Google Chrome';v='118', 'Not=A?Brand';v='99'",
"Sec-Ch-Ua-Mobile":"?0",
"Sec-Ch-Ua-Platform":"macOS",
"Sec-Fetch-Dest":"empty",
"Sec-Fetch-Mode":"cors",
"Sec-Fetch-Site":"same-origin",
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
},(res) => {
const contents = []
res.on('data',msg =>{
contents.push(msg)
})
res.on('end',()=>{
const res = Buffer.concat(contents).toString('utf-8')
console.log(res)
})
})
// 发送请求
req.end()
我这里请求了,结果乱码,尴尬,反正道理都一样,有的网站可以通过配置请求头,模拟浏览器发送请求,获得数据。
总结:通过以上两个方法爬取网站数据都有各种限制,不是长久之计呀。那么有更好的方法解决没得呢?答案肯定是有的。
Selenium
使用Selenium库爬取前端渲染的网页。
Selenium是一个Web应用的自动化测试框架,可以创建回归测试来检验软件功能和用户需求,通过框架可以编写代码来启动浏览器进行自动化测试,换言之,用于做爬虫就可以使用代码启动浏览器,让真正的浏览器去打开网页,然后去网页中获取想要的信息!从而实现真正意义上无惧反爬虫手段。
安装
npm install selenium-webdriver
选择webdriver组件
| 浏览器 | Component |
|---|---|
| Chrome | chromedriver(.exe) |
| Internet Explorer | IEDriverServer.exe |
| Edge | MicrosoftWebDriver.msi |
| Firefox | geckodriver(.exe) |
| Opera | operadriver(.exe) |
| Safari | safaridriver |
选择版本和平台,下载后放入项目根目录。
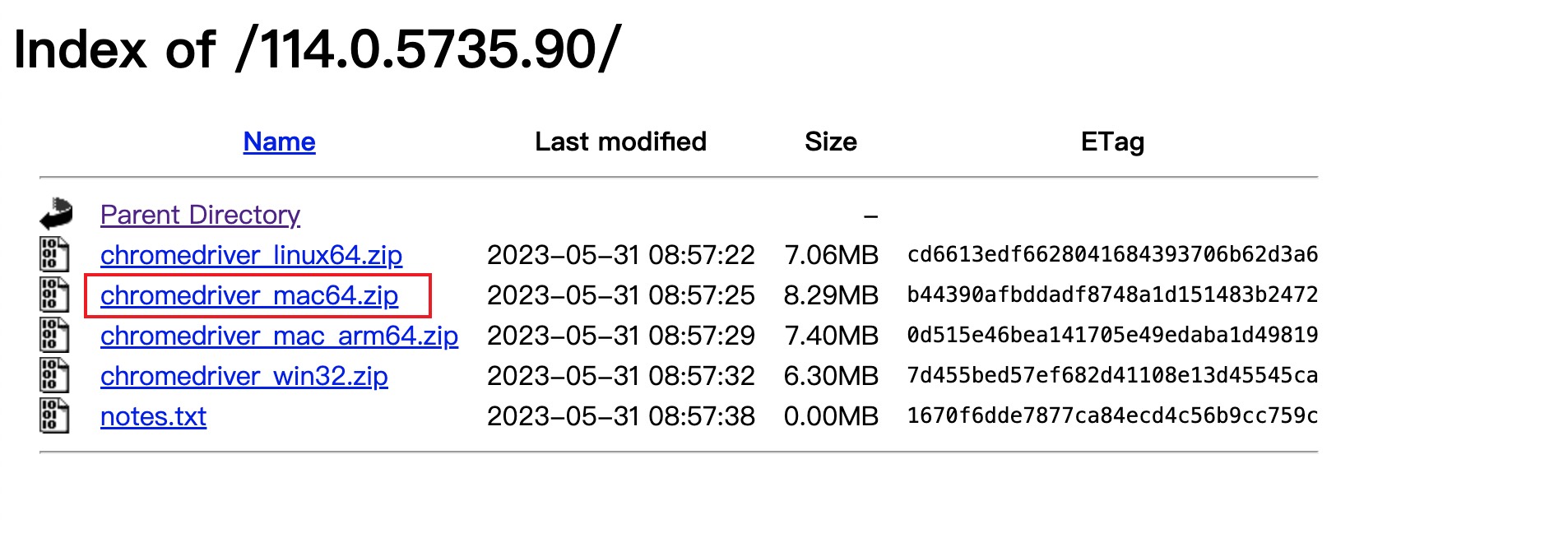
以上是我用mac选择的版本。
自动打开boss直聘搜索"前端"
使用driver.findElement()找到需要获取的dom,根据需求分析页面元素,获取其文本内容
const fs = require('fs');
//引入
const {Builder, Browser, By, Key} = require('selenium-webdriver');
// 打开浏览器
let driver = new Builder().forBrowser('chrome').build();
(async function example() {
// 打开boss网站
await driver.get('https://www.zhipin.com/chengdu/');
// 打开选择城市的弹窗
await driver.findElement(By.css('#header .nav-city .switchover-city')).click();
// 选择当前城市
await whileGetElements('city','成都')
// 查找input 输入关键字搜索 回车
await driver.findElement(By.name('query')).sendKeys('前端开发', Key.RETURN)
// 获取data
await whileGetElements('data')
})();
// 当前分页
let currentPageNum = 1;
// 最大分页
let maxPageNum = 1;
// while等待页面渲染完成
function whileGetElements(type,context){
return new Promise( async(resolve,reject)=>{
while(true){
let flag = true
try {
// 城市列表渲染完成 找到成都点击
if(type === 'city'){
const items = await driver.findElements(By.css('.change-city-dialog .dialog-container .hot-city-section .hot-city-section__list li'))
if(items.length){
for(let i = 0; i< items.length; i++){
let item = items[i]
let cityName = await item.getText()
if(cityName === context){
await item.click();
resolve(true)
break
}
}
} else {
flag = false
}
} else if(type === 'data'){ //获取 列表数据
const items = await driver.findElements(By.className("job-card-wrapper"))
let results = []
if(items.length){
// 获取分页最大值
if(maxPageNum === 1){
maxPageNum = await driver.findElements(By.css('.options-pages:nth-last-of-type(2)')).getText()
console.log(maxPageNum)
}
for (let i = 0; i < items.length; i++) {
let item = items[i]
// 获取岗位名称
let title = await item.findElement(By.css('.job-card-wrapper .job-name')).getText()
// 获取工作地点
let position = await item.findElement(By.css('.job-card-wrapper .job-area')).getText()
// 获取公司名称
let companyName = await item.findElement(By.css('.job-card-wrapper .company-name')).getText()
// 获取公司所在行业
let industry = await item.findElement(By.css('.job-card-wrapper .company-tag-list')).getText()
// 获取薪资待遇
let money = await item.findElement(By.css('.job-card-wrapper .salary')).getText()
// 获取技术要求
let background = await item.findElement(By.css('.job-card-footer .tag-list')).getText()
// 获取福利
let welfare = await item.findElement(By.css('.job-card-footer .info-desc')).getText()
results.push({
title,
position,
companyName,
industry,
money,
background,
welfare
})
}
console.log(results)
// 把数据存到data.json文件 这里可以存到数据库操作
writeFile(results)
// 自动翻页
currentPageNum++
if (currentPageNum <= maxPageNum) {
await driver.findElement(By.css('options-pages .ui-icon-arrow-right')).click()
await whileGetElements('data')
}
} else {
flag = false
}
}
} catch (error) {
// console.log(error.message)
if (error) flag = false
} finally {
console.log(flag)
if (flag) break
}
}
})
// 写入数据到文件
let list = []
function writeFile(data){
// 合并上次的写入
list = list.concat(data)
fs.writeFile("./test/data.json", JSON.stringify(list), 'utf8', function (err) {
if (err) throw err;
console.log("写入成功")
})
}
总结:以上是最简单的实例了,会了简单的,在搭建复杂的就容易些了。



